Managing a neuroscience data pipeline with airflow
A few months ago, I found myself with a backlog of data that needed preprocessing before I could start really analyzing it. I decided I need some kind of a scheduler to help push my data through the preprocessing efficiently.
I ended up deploying Airflow. Since then, the whole lab has started using it. This is how we made it happen.
The pipeline
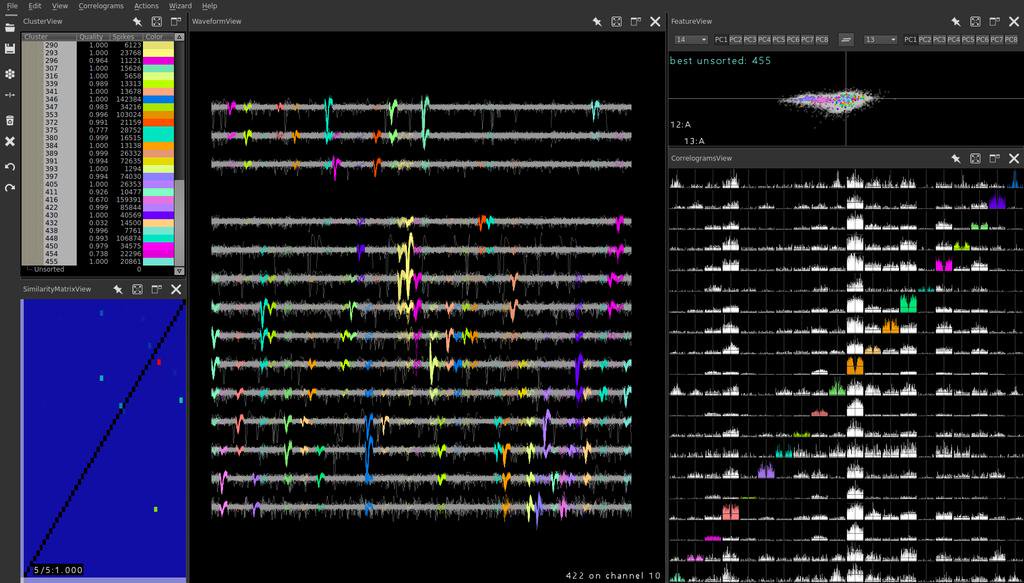
We have extracellular neural recordings and one of the major preprocessing steps is identifying neuronal spikes in the waveforms and clustering spikes that came from the same neuron. We are using the awesome package “phy” to do both of these steps, but there is a bit of preprocessing we need to do to prep our data for phy (de-noising the recorded signals and generating config files for phy).
This boils down to two major steps:
- De-noising with our own python scripts.
- Clustering with phy.
Step 1 is RAM-intensive & takes an hour or so. Step 2 takes many hours (possibly many days) and is CPU-intensive. Before airflow, I was using a simple bash script that runs these steps and a few others. But since I don’t want more than 1 or 2 batches in Step 1 at any given time, I’d fire off 2 batches, then log back in to the server a few hours later and run top to see what is running. If the batches have moved on from Step 1, then I can start a couple more batches. Check the log file to see if anything has failed and deal with those problems individually.
While “it works” it’s a pain to need to constantly be wondering what the status of all of this. If I’m not in the lab, I need to connect to the VPN then shh into the server. And that’s if I remember and I’m not asleep or whatever.
What I needed was a way to just add an analysis batch to a queue that only allows 1 or 2 batches to be running Step 1 at a time and no more than the number of processors running step 2.
We talked about SLURM or SGE but we’re just basically just running python scripts on one server. These tools are a bit of overkill for our needs.
This is what brought me to airflow, which was developed and open-sourced by Airbnb. The basic idea of Airbnb is that you define a set of Tasks and define dependencies in between Tasks, thus creating a Directed Acyclic Graph (DAG). Importantly, Tasks can get assigned to Pools. So if there are more Tasks that need run that slots available in the Pool, Tasks will get added to a queue and will execute once a slot opens in the Pool.
Boom. Looks like airflow will do exactly what we need out of the box.
However, I quickly discovered that this isn’t quite true.
Airflow was designed for an enterprise setup where you need to do things like “analyze the day’s log files and dump the results into a database”. What this means in Airflow terms is that you have a single DAG that runs every day (or on whatever schedule you want). This doesn’t really work for my data. I need to be able to run a DAG whenever I want with the appropriate parameters for that run.
I don’t want to re-hash topics covered in the wonderful Airflow tutorial, so I’m going to pickup where it left off.
For one batch, use one DAG
There are a few features of Airflow’s DAG’s that will let us do this.
First, instead of running DAGs are regular schedule, we can set the schedule_interval argument to None or @once.
dag = DAG(dag_id,
default_args=default_args,
schedule_interval='@once',
)
With schedule_interval=None, you’ll need to manually run the dag at the command line with airflow trigger_dag dag_id when you are ready. If you are comfortable with the DAG getting run immediately, @once'
Generate DAGs dynamically
Second, since DAGs are defined as instances of DAG objects, we can generate them dynamically. For example, we can list the dag_ids in a text file and loop over it. Adding a new dag is as easy as appending a new line to the batches.txt file.
with open('batches.txt','r') as f:
for line in f:
dag_id = line.strip()
dag = DAG(dag_id,
default_args=default_args,
schedule_interval='@once',
)
…
globals()[dag_id] = dag
For the example above, I iterated over a list of dag_ids, which is fairly boring. But you can see that it would not be hard to iterate over any set of parameters needed for a pipeline. For example, in my pipeline, I have two parameters: BLOCK identifies the batch that I want to process; it is used as the dag_id (because it is unique) and to set paths. OMIT is a list of my recording channels that I need to omit from the analysis & it’s a necessary parameter for Step 1.
Thus, I have file with BLOCK and OMIT separated by a tab.
Pen03_Rgt_AP2350_ML1400__Site04_Z2023__B957_cat_P03_S04_Epc17-18 Port_20,Port_21,Port_2,Port_23,Port_32,Port_29
Pen03_Rgt_AP2350_ML1400__Site04_Z2023__B957_cat_P03_S04_Epc29-33 Port_20,Port_21,Port_2,Port_23,Port_32,Port_29
Pen01_Lft_AP2500_ML1350__Site05_Z1536__B997_cat_P01_S05_Epc01-04 Port_16,Port_22,Port_30,Port_27,Port_28,Port_32,Port_29,Port_12,Port_31
And I can generate DAGs by crunching this file.
with open('/home/jkiggins/airflow/dags/blocks.tsv','r') as f:
for line in f:
args = line.strip().split()
if len(args) < 2:
continue
BLOCK = args[0]
OMIT = args[1]
dag = DAG(BLOCK,
default_args=default_args,
schedule_interval='@once',
)
make_kwd_task = BashOperator(
task_id='make_kwd',
pool='RAM',
bash_command=make_kwd_command,
params={'source_dir': '/home/jkiggins/data/mat/' % BLOCK,
'target_dir': '/home/jkiggins/data/phy/' % BLOCK,
'omit': OMIT},
dag=dag)
phy_task = BashOperator(
task_id='phy_spikesort',
pool='CPU',
bash_command=sort_spikes_command,
params={'target_dir': '/home/jkiggins/data/phy/' % BLOCK},
dag=dag
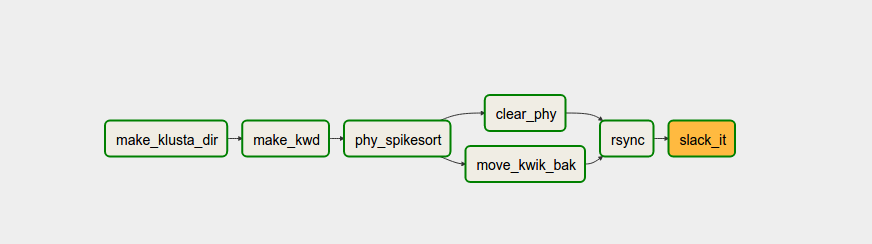
phy_task.set_upstream(make_kwd_task)
…
Now that the whole lab is using it, it takes a bit of care not to step on each other’s toes. Airflow looks for dags in a shared folder (which we should probably put under version control). We’re basically just using one file per person/project. In addition to the RAM and CPU pools, we have a GPU pool for my labmates doing deep learning.